Recommender system for Letsbar

Recommender systems are a wide branch in a sphere of machine learning. Many successful businesses, like Amazon, Pinterest, Google etc. are using recommender systems to be useful for current users. Because interests have become more complex, size of the user data profile is becoming wider and simple marketing is getting weaker. Recommender system is a solution how to stay on top in the current business world.
Project
Our teem is have a strong machine learning experience. But a task of recommender system creation was new for us and we needed to extend our knowledge in it.
Letsbar is a restaurant booking service, where people may browse for interesting restaurants, cafes, bars, concerts, events etc. and book tables. Not so long time ago it was implemented a rating system to evaluate visited events or restaurants.
The task given for us was to create a system, planned to integrate to the server, that can make predictions what restaurant or other event a user would be interested in to book and go for in a future.
Basic idea was in a marketing theory of personalization. We stated that every user has its own preferences for food, drinks, atmosphere etc. And every user deserves to get not just a simple advertisements, but a useful advice.

Research & Development
After a thorough research we selected many approaches and took the best ones. Were discovered model based approaches of matrix factorization using SVD, NNMF, PCA. Discovered few libraries like Spotlight, LightFM, Surprise.
These three libraries were created by amateurs and are in open source: Spotlight, LightFM, Surprise.
Were deeply discovered techniques of KNN approach, using cosine similarity. Explained a problem of -evaluation with popular metrics like precision and recall, F-scores, RMSE, explained variance ratio etc. Mathematics knowledge was strongly improved and we were ready to start building our own recommender system.
We chose collaborative filtering approach with idea of collecting users into groups by interests and predict new experience for them. There is a division of this approach into two ways, described next.
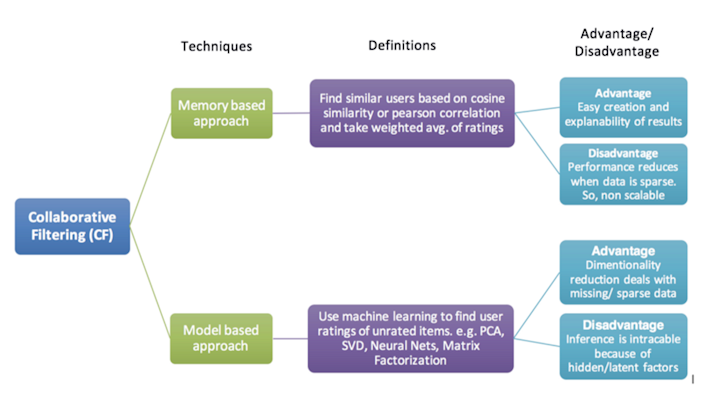
Problems
In the beginning of the project we faced with a problem of lack of data. We had not enough data of users marks to make explicit feedback model (using graded ratings to evaluate user/item interaction) and even for implicit feedback model (using just a fact of visit or not). We had not even enough features to describe items and users to make a simple solution.
Solution
Was decided to create first MVP model, using KNN approach. We constructed features for users and described restaurants in the same case. While constructing features, we used NLP technique with help of such library like Gensim to evaluate unique features and create wider and smarter features range with division into semantic groups.
Next picture illustrates this process with a small set of tags, decomposed to two dimensional space.
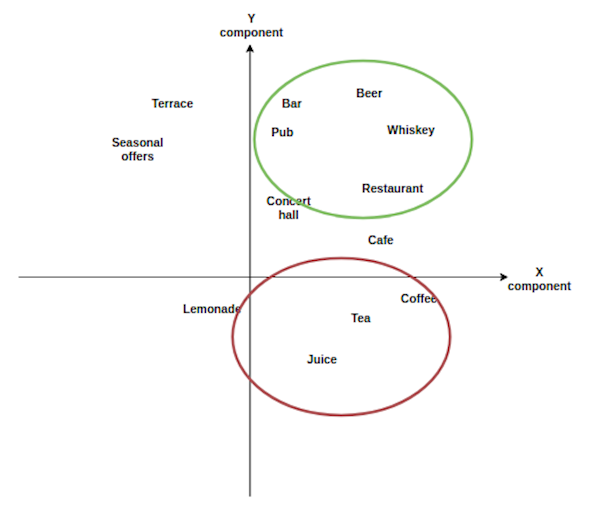
MVP model used cosine similarity to find the most similar restaurants or events to user preferences.
Meaning of this measure is a cosine between two vectors of features. It is smarter than simple filtering or even Euclidean metrics, because cosine similarity is looking for “same mood” or mathematically “same direction vectors” of user unique preferences and place description, while other metrics just compare absolute distances between them.
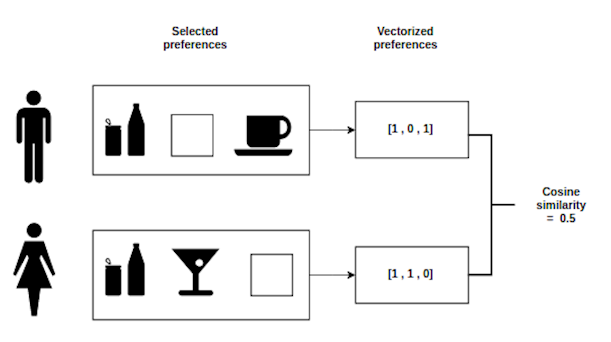
Short example
We took 5 real users and select 5 features for them from the whole range. Features are the unique words, that can briefly describe a place, like ‘beer’, ‘tea’, ‘cake’ etc. Each value is in range from 0 to 1, where zero is totally negative and one is totally positive attitude to feature.
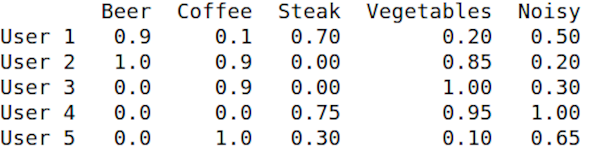
And we took 6 restaurants with the same feature vectors structure.
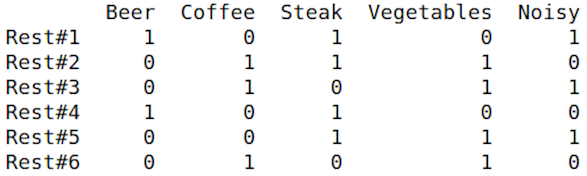
Here was used cosine similarity to define top 3 similar restaurants for users. The value of similarity (from 0 to 1) was written like a predicted mark to this place.
Let’s see for User 1 results. Green colour corresponds to recommendations. We state that recommendation is a value greater or equal to 0.5.
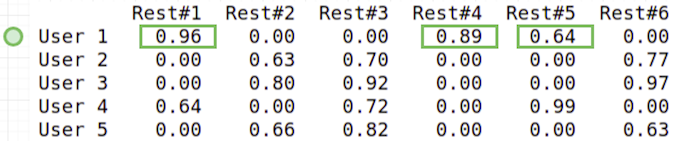
User 1 is some kind of “beer and steaks lover, preferring noisy restaurants”. For User 1 the best result is Restaurant 1 with description “noisy bar with beer and steaks” and similarity 96%. Next is Restaurant 4 like “we have only beer and steaks” and 89% similarity. It was an immediate recommendations, based on the users and places profiles.
Generally, this process is illustrated on the next picture with another data.
We took their similarity approximations as the future marks to recommended restaurants and additionally asked them to rate given results.
For users we made a grade from 1 to 5 with step 0.5. If user gives us the marks, we will use them, if do not we will use predicted cosine similarity values. All values are scaled to range from 0 to 1.
After collecting enough data of marks we can use matrix factorization approach. It is a good approach to classify users by their latent factors.
Latent factors are the hidden connections between users, based on their rating history. We highlighted by green color true positive results (≥0.5) and pull down threshold for new recommendations to ≥ 0.1 and highlighted them by yellow. Red ones are negative answers.
The final result for User 1 is the next:
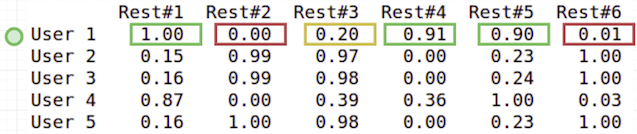
We totally predicted already rated restaurants right (true positive) and saw that User 1 had got a new mark 0.2 for Restaurant 3. But 0.2 is rather low to recommend it in general case.
This place is new for user and we took lower threshold. Restaurant 3 is a “noisy coffee place with salads”, sounds like some kind of cafeteria in a mall. But this user had no such preferences.
Why was it recommended? Explanation:
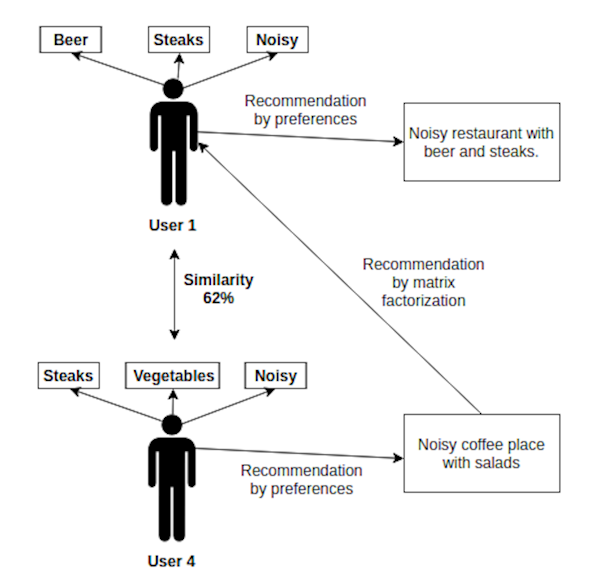
User 4 is 62% similar to User 1 because they both like steaks (0.7 and 0.75) and like noisy restaurants (0.5 and 1), but User 4 likes vegetables and has recommendation by preferences Restaurant# 3 (noisy coffee place with salads) with 72% probability to like it.
After matrix factorization model we stated our beer lover (User 1) would be also vegetables and coffee lover and recommended restaurant #3.
It was a short example how collaborative filtering works and we discovered latent lover of coffee and salads in a beer and steaks lover.
Matrix factorization
Model was tested with such techniques like SVD, NNMF, PCA, ALS. Best results were with SVD and ALS (evaluating by RMSE).
We had over 100000 users and 50 connected to a system restaurants in the city. And 80% of users have at least 5 marks. Sparsity of such data rather high, but it is enough to make good predictions.
The model factorized initial matrix of users/places with ratings into two matrices of items segments and user segments.
Truncated example:
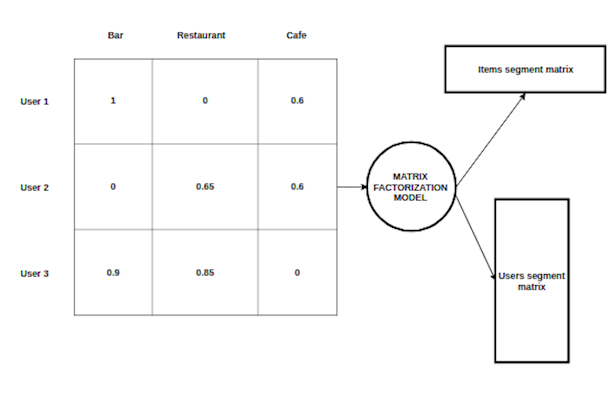
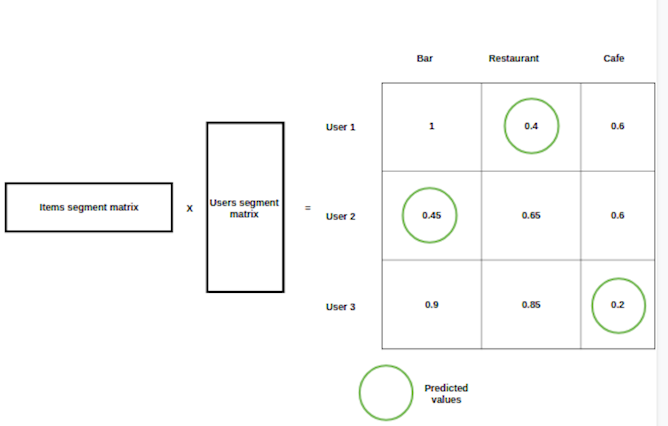
After factorization, a dot product of the two received matrices will be an approximation of the initial matrix with predicting the zero values with weights what we can interpret like probability of user positive attitude to current restaurant. A threshold of recommendation is lower for approximated values then for initial.
We used Spotlight library, with PyTorch and CUDA to make our predictions better and faster. Precision of such model was 90% with recall 99%. It means we totally know current users preferences in restaurant selection and advised them some new experience in it.
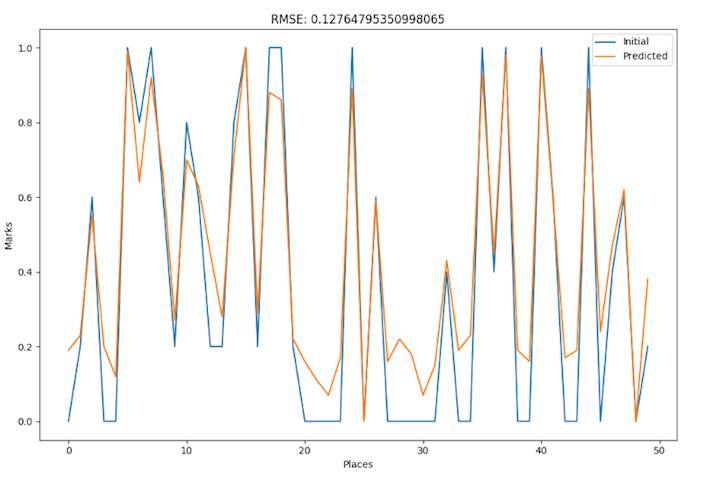
Next picture is a plot of visits history of a random user. The blue line is the current user experience and the orange one is a prediction.
These two lines are converging. It was evaluated by quiet low RMSE = 0.1276.
Those parts of the blue line with marks coordinate equals to zero are predicted higher by orange line and we may interpret them like new recommendations for this user.
Achievements
After thorough work we got two models. First one working with memory based approach and KNN by cosine similarity, that showed pretty good recommendation results, predicting perfect recommendations for user by their preferences. And we made a matrix factorization model with precision score 0.9 and recall 0.99. Last model made a good collaborative filtering and predicted totally new restaurants for users. We deeply discovered and understood mechanisms of such models and ready to improve them.
What’s next?
Recommender systems are extremely fast developing sphere and still has many open questions. One of them was evaluation metrics.
How can we evaluate new experience for user without any previous experience? It means that user had zero and we advised one (in binary explanation). How can we evaluate it right? Do we need to invent penalties for false positive results or not? Or we just need to concentrate on current user experience and advise items that we confident in?
It depends on a current task and business vision and goes into deep philosophy questions. But we are ready to solve it.
In the nearest future we are planning to invent such algorithms like LSTM models, real-time prediction models and new evaluation metrics to move recommender systems forward.
Conclusion
Our team have got a great experience in recommendation system developing and data analysis. We are ready for new challenges.
Let’s discuss the next great project!
To enable comments sign up for a Disqus account and enter your Disqus shortname in the Articulate node settings.